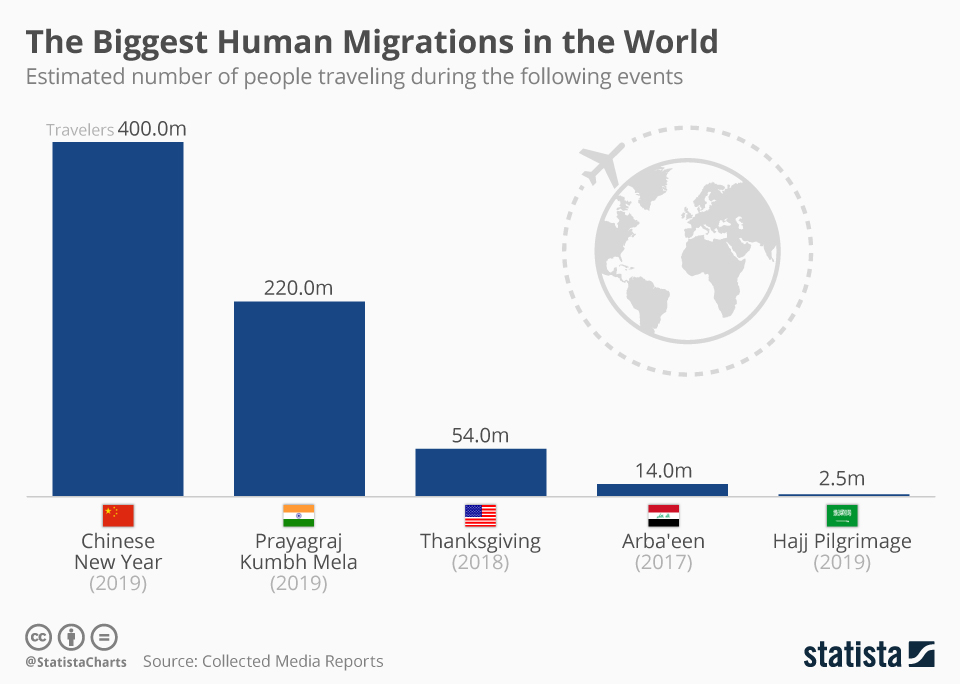
IBM Datacap
Intelligent document capture
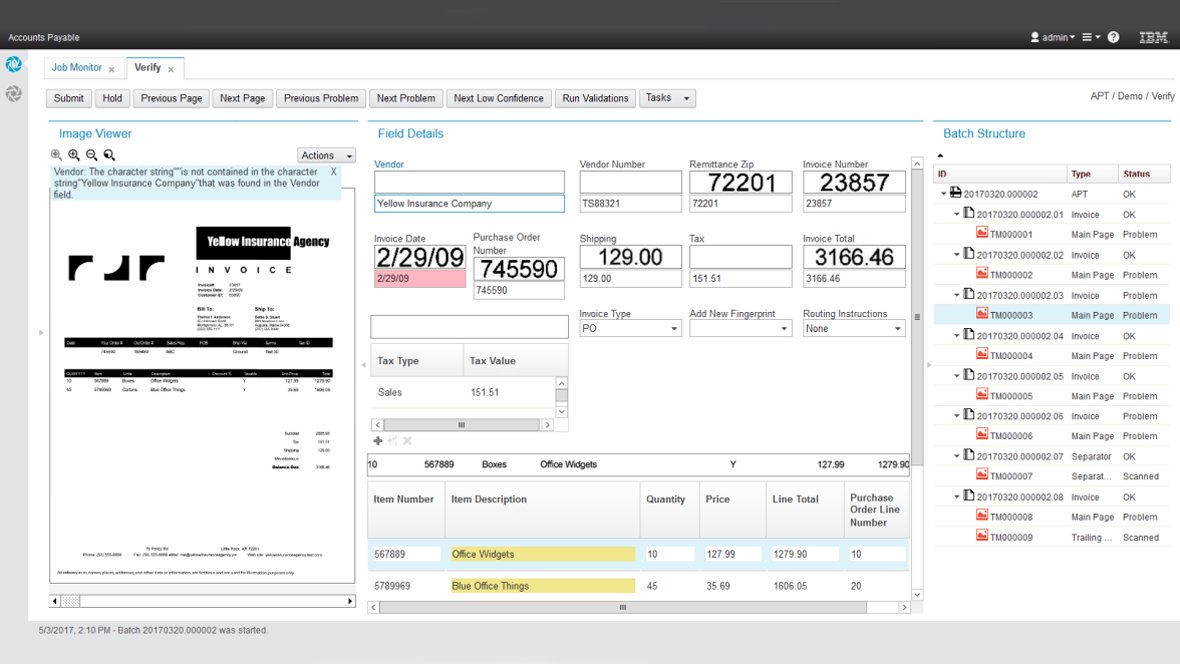
IBM® Datacap helps you streamline the capture, recognition and classification of business documents and extract important information. Datacap supports multiple-channel capture by processing paper documents on scanners, mobile devices, multi-function peripherals and fax. It uses natural language processing, text analytics and machine learning technologies, to automatically identify, classify and extract content from unstructured or variable documents. The software can reduce labor and paper costs, deliver meaningful information and support faster decision making.
Advanced document capture
Supports multi-channel input from scanners, fax, e-mails and digital files (such as PDF) as well as images from applications and mobile devices.
AI infused intelligent processing
Uses machine learning to automate the processing of complex or unknown formats, as well as highly variable documents that are difficult to capture with traditional systems.
Export to other targets
Enables you to export documents and information to a range of applications and content repositories from IBM and other vendors.
Highly adaptable rules-based capture
Offers configuration of capture workflows and applications using a simple point-and-click interface to speed deployment.
Role-based redaction
Enables documents to be redacted automatically, based on the role of the requester, blocking out information according to a user's specifications.